Notes from the original paper
Toy models used — small ReLU networks trained on synthetic data with sparse input features.
What do they mean by “sparse” features?
Most of the values in the feature space are zero.
Why?
To investigate how and when models represent more features than they have dimensions — this is superposition.
- Compression. When features are sparse, superposition allows compression beyond what a linear model would do but at the cost of “interference” that requires nonlinear filtering.
Example
Consider a toy model where we - train an embedding of five features of varying importance (scalar multiplier on MSE loss) in 2D, add ReLU afterwards for filtering and vary sparsity of the features.
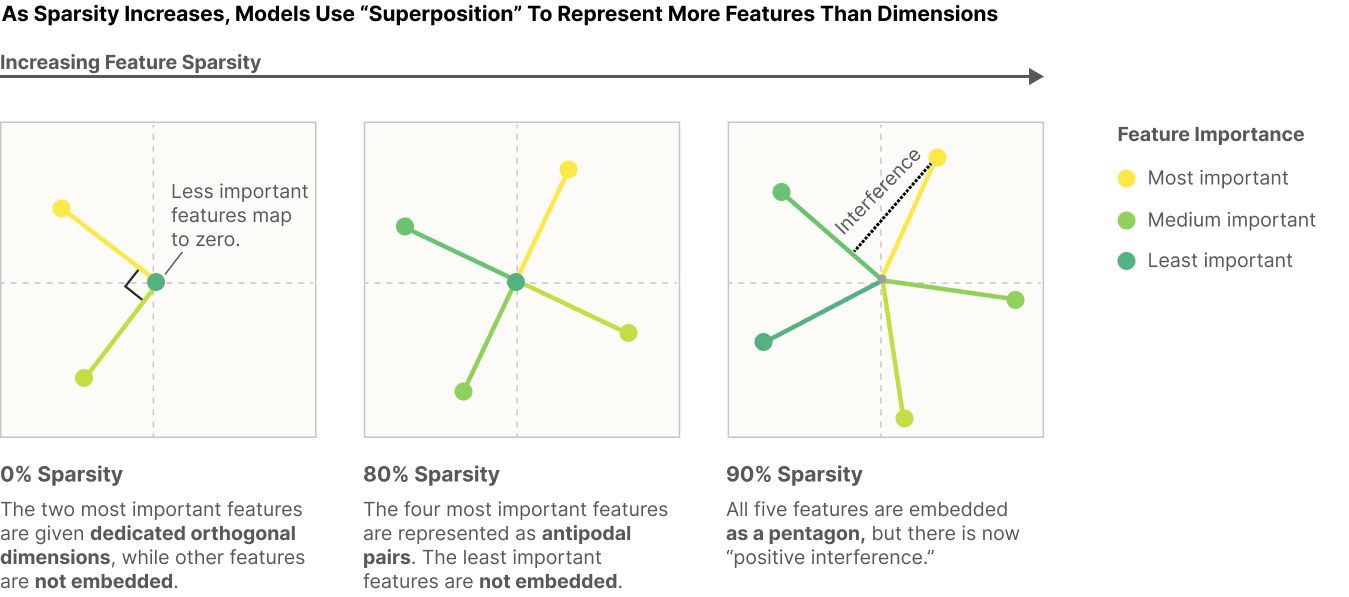
Observations
- If the features are dense, the model learns to represent an orthogonal basis of the most important two features (similar to PCA), others are mapped to 0. As the sparsity increases, the lesser important features also start to appear in the embedding.
- Here the number of dims = 2 but the features represented are more than in case of higher sparsity, models use “superposition” here.
- However, there might be some interference as shown in 90% sparsity case — basically, a feature representation will have a non-zero component along another feature representation.
Models can perform computation while in superposition.
- Models can put simple circuits computing the absolute value function in superposition. (What?)
- Hypothesis: Neural networks observed in practice noisily simulate larger, highly sparse networks. — Models can be thought of as doing the same thing as an imagined much-larger model representing the exact same features but with no interference.
Feature superposition in other places! (Read later)
- Linear Algebraic structure of word sense, with applications to polysemy (TACL 2018, Arora et. al)
- Decoding the Thought Vector (2016, G. Goh)
- Zoom In: An Introduction to Circuits (Distill 2020, Olah et. al)
- Softmax Linear Units (Transformer Circuits Thread 2022, Elhage et. al)
- Compressed Sensing (IEEE TIT 2006, Donoho et. al.)
- Local vs. Distributed Coding (Intellectica 1989, Thorpe)
- Representation learning: A review and new perspectives (IEEE TPAMI 2013, Bengio et. al.)
What do they show in this paper?
- Interpreting NNs as having sparse structure in superposition is not only a useful post-hoc interpretation but the “ground truth” of the model.
- When and why? → “phase” diagram for superposition.
- Why neurons are sometimes monosemantic and sometimes polysemantic?
- Monosemantic → respond to a single feature.
- Polysemantic → respond to multiple features.
- Why neurons are sometimes monosemantic and sometimes polysemantic?
- Superposition exhibits complex geometric structure based uniform polytopes.
- Uniform polytopes
- Class of regular polytopes in any number of dimensions. Think regular polygons in 2D, regular polyhedra in 3D.
- *Conditions for uniformity
- Vertex-transitivity: all vertices are equivalent under the symmetries of the polytope.
- Edge-transitivity: all edges are equivalent.
- Face-transitivity: all facets (faces) are equivalent.
- Vertex figures are regular: Figure formed by the intersection of the polytope with its facets must be a regular polytope of one dim lower.
- Preliminary evidence that superposition may be linked to
- adversarial examples
- grokking (?)
- theory for the performance of mixture of experts model.
- Uniform polytopes
Definitions and Motivations: Features, Directions and Superposition
- They think of features of inputs as directions in activation space. Like in the example above — there are 2 dim in activation space and 5 features in the input.
- “Linear Representation Hypothesis”. Two separate properties
- Decomposability → Network representations can be described in terms of independently understandable features.
- Linearity → Features are represented by direction.
Notes from Neel Nanda’s Walkthrough Video
- High-dimensional spaces are not intuitive to understand.
- It is easier to fit a lot of features (nearly orthogonal) in very high-dimensional spaces.
- Interference vs. Internal Representation. The linear map encoder projects input into 2 dimensions and read-out using dot product (basically projecting into some direction) → from 2-dim to 5-dim. Key point is that encoding and decoding are not inverse operations. Project down operation is not inverse of embed up.
- Superposition in Toy models vs. Real transformers. Discussion on where transformer might be compressing. Residual stream has much lower dimensions (bottleneck dimensions). Non-linearities cause more interference.
- About non-privileged basis →
- Features are not invariant under a change of basis.
- → will change the internal representations.
- This is a non-privileged basis.
- Features are not invariant under a change of basis.
- Some weird stuff!
- Neel says that neural networks in computers are computational objects not abstract linear algebra objects. So in computers, the way you represent vectors as floats in a computer is always privileged.
- Floating points represented in a computer — 32 bits (MSB - signed bit (+1 or -1), floating point representation in binary, exponent bit, another binary string).
References
[1] Elhage, et al., “Toy Models of Superposition”, Transformer Circuits Thread, 2022.
[2] A Walkthrough of Toy Models of Superposition w/ Jess Smith - YouTube